
kernel知识点记录
学kernel的悲伤的事情,就是有时间学的时候发现之前学的都忘记了:(
由于发现kernel的知识点还是比较多,所以还是记录一下方便我忘记后速看,混杂很多自我理解和废话和大量的原文,长期更新
保护
SMEP
SMEP(Supervisor Mode Execution Protection),是内核的保护措施,当用户在ring0模式时,执行用户空间的代码会触发页错误。在Arm中叫PXN。
一般可以看qemu的启动脚本的参数确定有没有开SMEP保护,SMAP同样是这个方法。
系统会根据CR4寄存器的值判断是否开启SMEP保护,如果CR4寄存器第20位是1,保护开启,否则关闭。
一般用mov cr4, 0x6f0关掉SMEP
SMAP
让ring0模式的用户无法读写用户代码,SMEP是执行这个是读写,其他的差不多
CR4寄存器
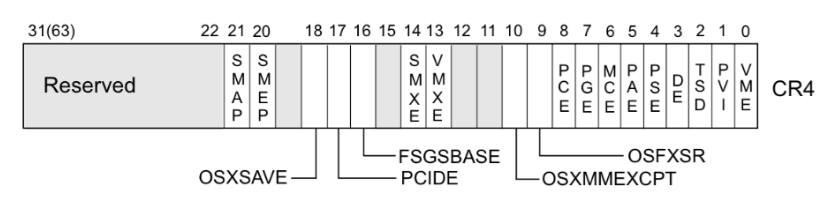
20位是SMEP,21位是SMAP
内核镜像相关
vmlinux
编译出来的原始内核文件。里面有符号表,不能直接用来加载,但是可以用来kernel-debug
bzImage
压缩后的内核文件。bz表示”big zImage”。内核比较大最好用这个,有更好的压缩率
zImage
和bzImage相比没有big,经过gzip压缩后的Image,一般用作uboot的镜像文件。解压到比较小的内核
vmlinuz
丢失符号信息,解压可得vmlinux,可引导可压缩的内核。
页表
因为进程独占虚拟地址空间,不同进程的虚拟地址空间相互隔离,而为了防止地址冲突问题,虚拟地址和物理地址不是线性对应的,而是通过页表像map数据结构一样映射的。
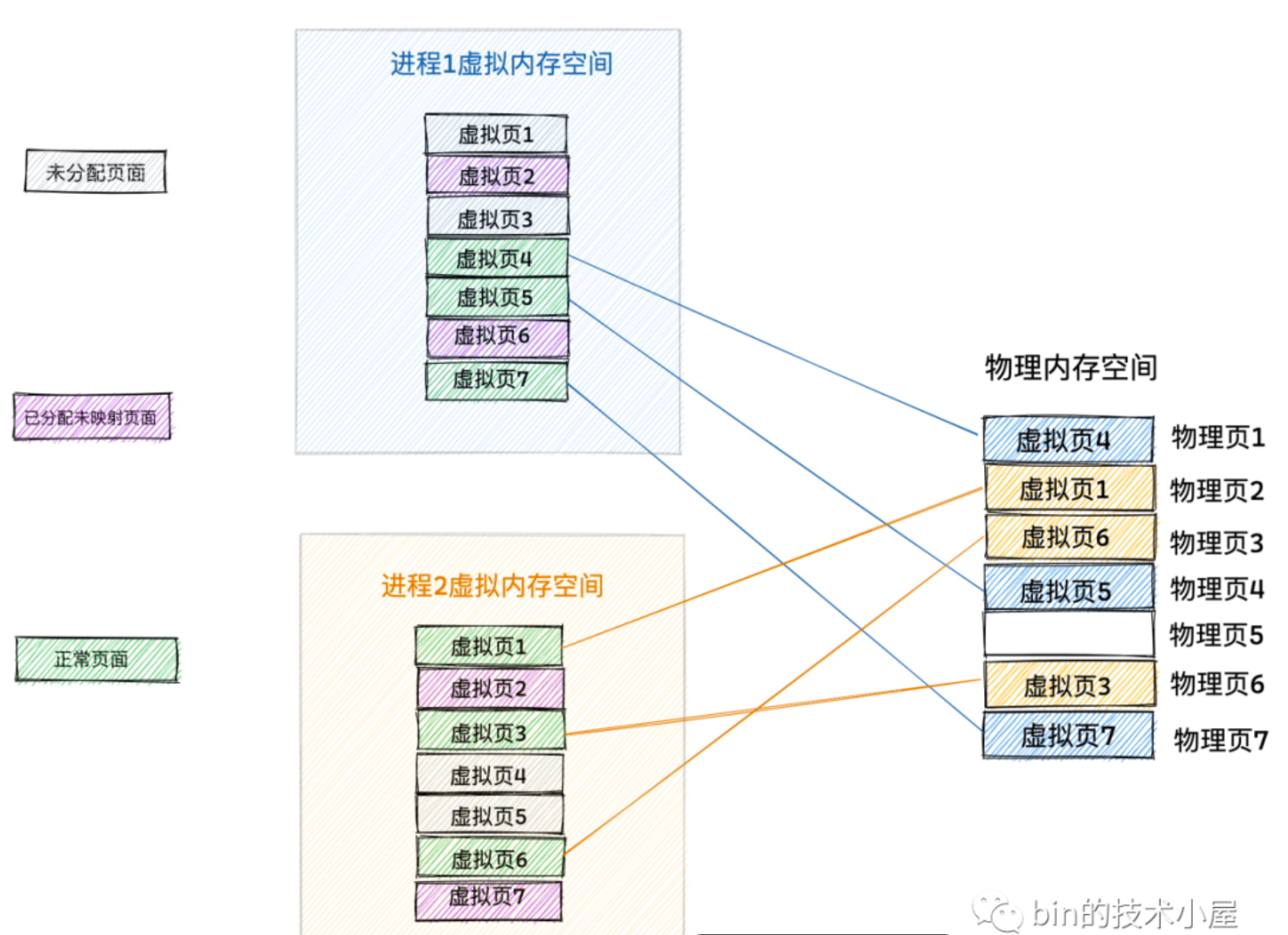
不同的进程会维护自己的一个页表,来管理各自虚拟内存空间的映射关系和各自访问物理内存的权限。
内核在物理内存里分配一个页存储进程的内存映射关系,叫页表,所以页表本质就是一个物理内存页。
页表中存储的是页表项PTE,保存了进程虚拟空间的虚拟页和物理内存页的映射关系。size和指针一样,32位4个字节64位8个字节。
由于单级页表的几种缺陷:
- 物理地址必须连续
- 耗费空间大,比如映射4m的物理内存需要4k的页表,还必须连续不然没法用数组访问的形式
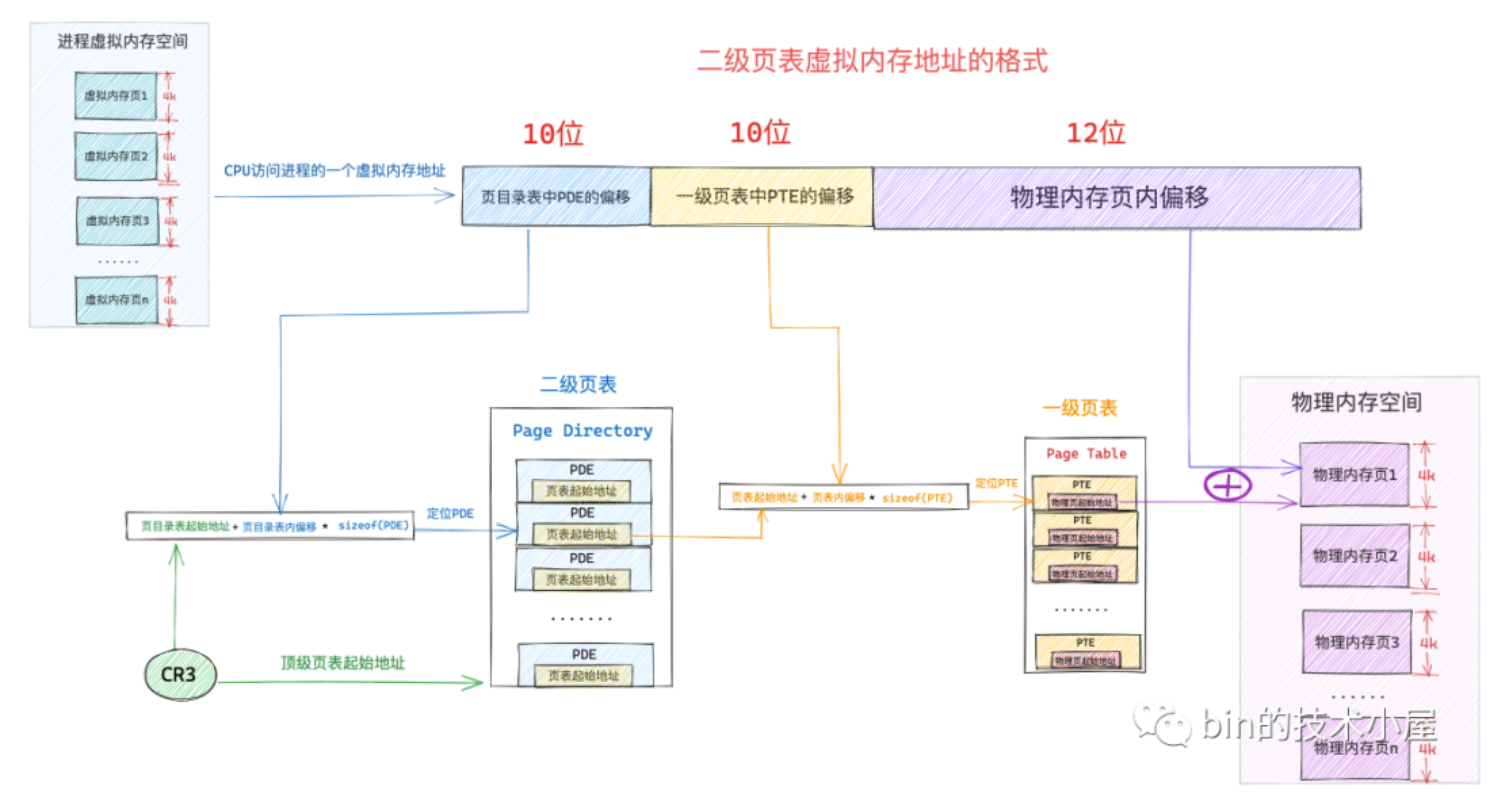
所以引入了多级页表,原理也差不多,不过一级页表是直接映射到物理内存,二级页表是直接指向一级页表。一个一级页表的PTE表项映射4k,一个一级页表映射4m,二级页表就可以映射4g的物理内存了。相比只设置一级页表的情况省了非常多空间。二级页表的PTE一般叫页目录项(PDE,Page Directory Entry)
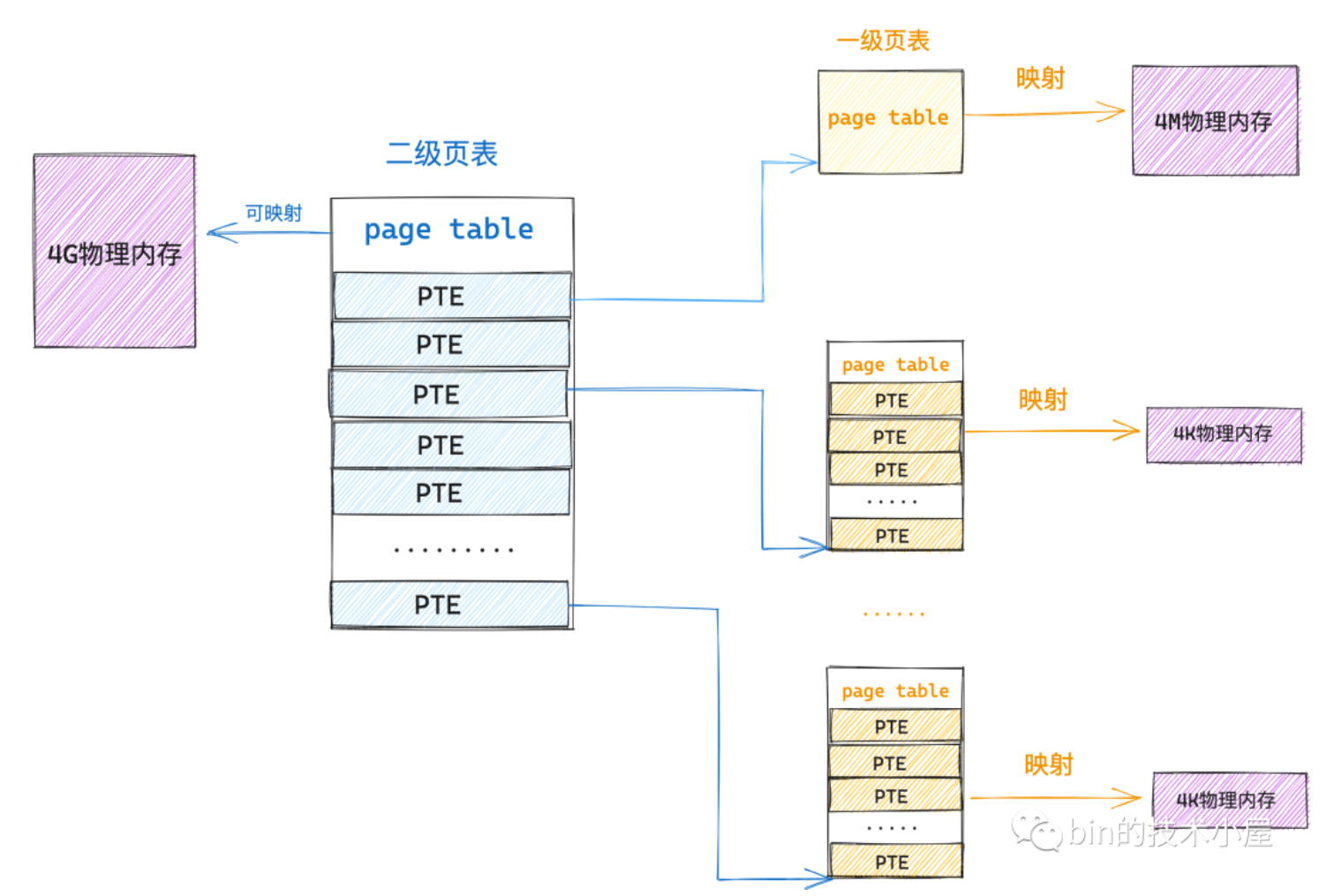
实际情况的话,如果访问一个4k的物理内存(一页),内核会创建一张一级页表,然后用页目录表PDE索引起来。这张一级页表的一个表项PTE就映射到对应的物理内存页之中。
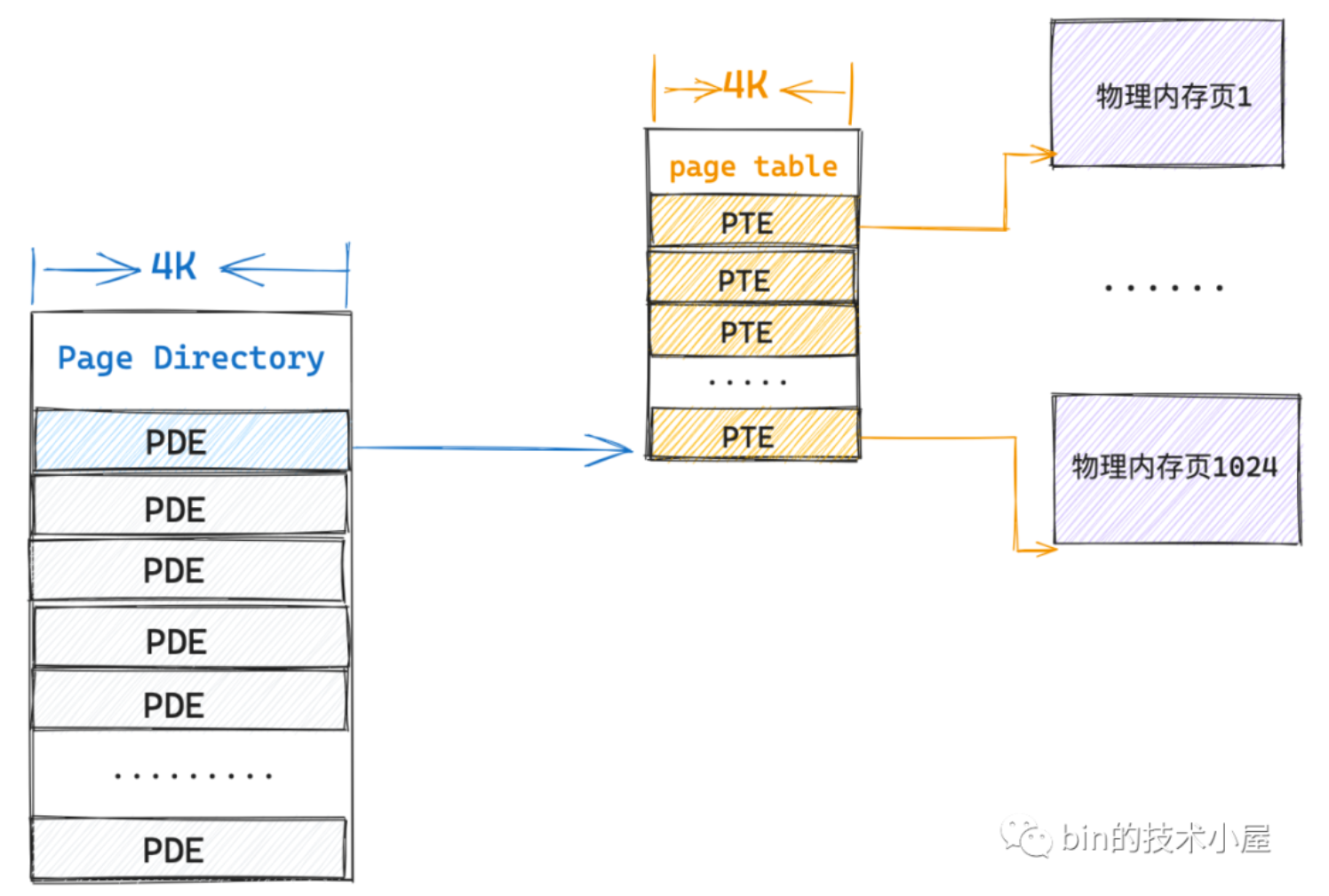
由于局部性原理,如果访问该物理内存的连续的物理页直到消耗完改一级页表的所有表项,也是只需要4k一级页表+4k二级页表的内存。
且一级页表的物理地址不需要连续,只是一级页表内的PTE需要物理地址连续。
当内存紧张的时候,不经常使用的一级页表会被swap out到磁盘中,当使用到该页表映射的内存的时候再被swap in到内存中。
因为页表本质是物理内存页,所以也会被缓存到CPU高速缓存中加速下一次的访问速度。
这个会被拆解成页表内偏移和物理内存偏移的虚拟内存地址就是进程的虚拟空间的地址。因为每个进程页表不一样所以可以访问到不同的物理内存。
应用二级页表后,首先cr3存取的是二级页表的起始地址,也就是顶级页表的起始地址了。而且虚拟地址的截取方式也改变了,加上了PDE的偏移和PTE的偏移,很合理。其中32位的地址分割成10-10-12.
32位PTE
32位的PTE结构如下

P位代表映射的物理内存页是否在内存中,可能被swap到磁盘里去了。虚拟内存寻址后直接看P位,如果为0触发缺页异常。
R/W代表进程对该物理内存的读写权限,如果1就是可读写,0就是可读。如果对只读页面写会触发写保护中断异常的page fault。用于写时复制(COW)场景。
父进程通过fork系统调用创建子进程后,父子进程的虚拟地址空间一模一样,页表同样也一模一样。父子进程的页表的PTE指向的是同一个物理页面,这肯定是不行的。此时内核会将父子进程页表的PTE改成只读,并将父子进程同样映射的这个物理页面的引用计数+1
当父进程或者子进程对该页面进行读写操作的时候,如果是子进程首先进行写操作,写入页面时发现该物理页面是只读的,于是触发写保护中断。进入内核后,在缺页的中断处理程序中发现该物理页面引用计数大于1,这证明了有不止一个进程在共享这个物理页面,此时会触发写时复制,内核会寻找一个新的物理页面,然后将当前的物理页的内容复制到新的页中,随后将子进程的页表的对应的PTE改成新的页并将R/W设置为1,将原来的物理页的引用计数-1,最后完成写操作到这个新的页之中。
父进程要是读写该物理页,同样会触发写保护中断,再缺页中断处理程序检查引用计数的时候发现是1,证明没有其他进程也在共享这个物理页,就会直接把PTE的R/W设置为1然后正常写了。
U/S(2)值为0只有内核才可以访问,值为1用户空间进程也可以访问。
32位PDE
PDE的结构如下

主要看看第7位PS位,如果ps位设置为0,就是PDE就是正常的页目录表项,指向一级页表的起始内存地址。如果设置为1,就是指向一个4M的物理内存页。
四级页表和一级到二级的改变差不多,不记录了类比一下就行了
64位PDE
因为一页的大小还是4k,而一个PTE占用了8字节,所以一个一级页表只能存储512个PTE。9个bit存储即可。
总的来说64位的四级页表结构导致的虚拟地址的解析方式如下
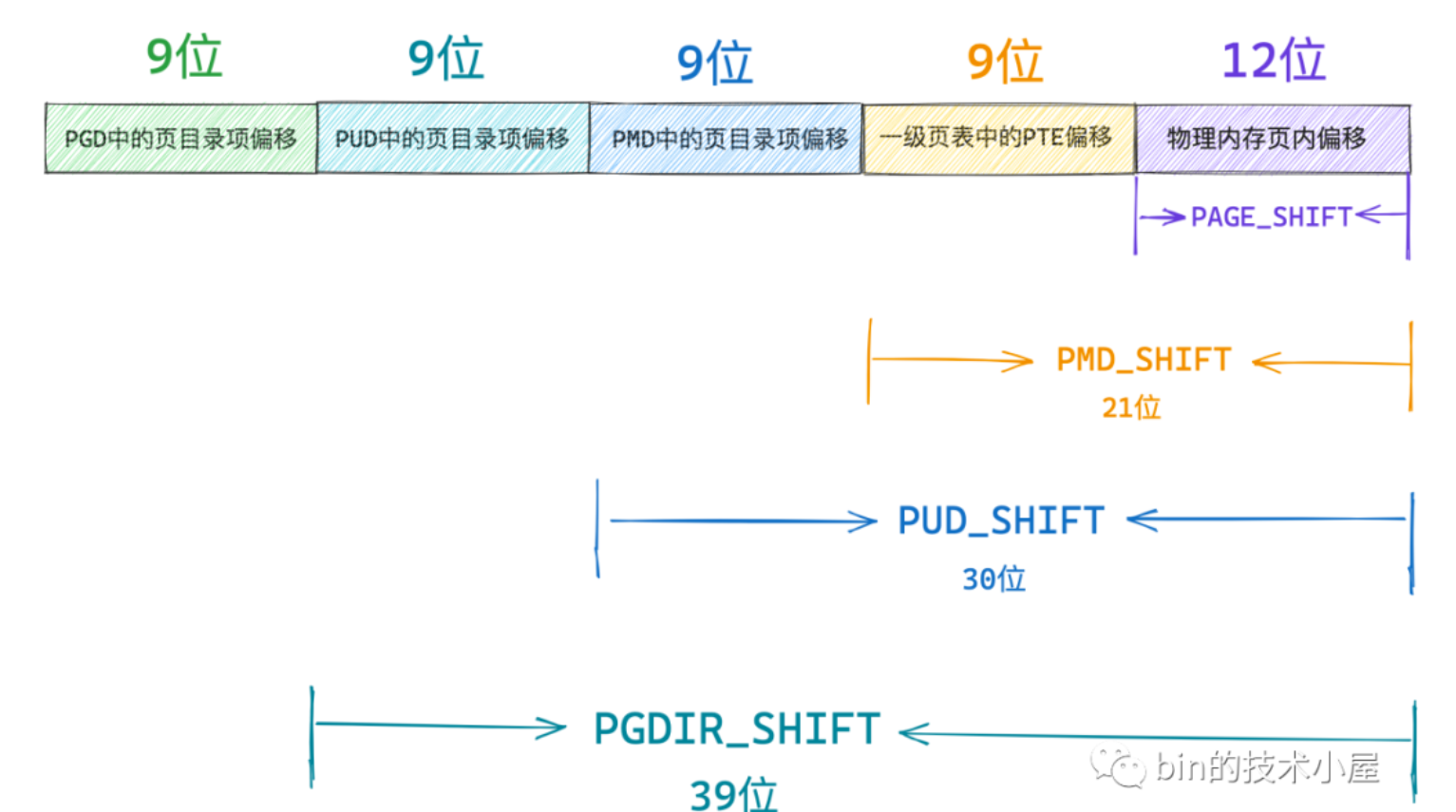
映射物理内存大小:4K->2M->1G->512G
64位PTE

63位XD非常的搞笑XD,所以记录一下。值为1代表对应物理内存的页面的数据可以执行。
MMU
其中,这些所有的寻址操作都是在地址翻译硬件——MMU中实现的,可以极大的提高效率。不然CPU疯狂访问内存,效率会非常差。
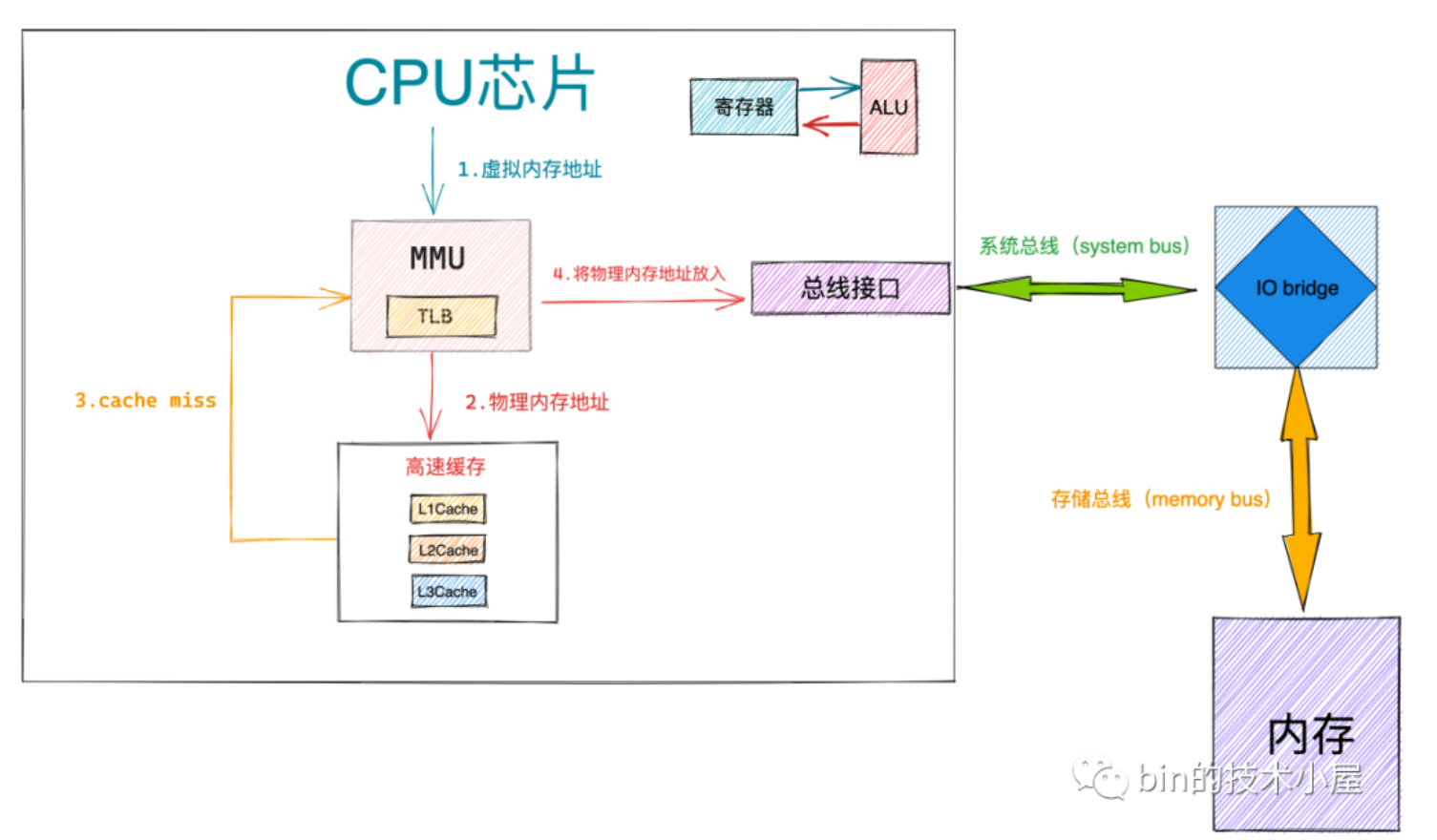
MMU也有硬件缓存,存PTE的,叫TLB(Translation Lookaside Buffer)。和CPU的高速缓存一样,提高查找效率。有TLB后虚拟内存地址传入MMU中后先会在TLB里寻找当前的虚拟内存地址翻译成PTE后是否有缓存,如果有的话直接省去翻译步骤返回对应的PTE,否则先把当前PTE加入TLB中后用MMU翻译。
CPU芯片将虚拟内存地址传入MMU中,MMU翻译出物理内存地址后,首先去CPU的高速缓存中寻找有没有缓存该物理地址的数据,如果miss了就把物理内存地址放入总线接口,通过系统总线经过IO bridge后走存储总线去访问内存。读取后IO bridge将存储总线传回来的数据信号转成系统总线的数据信号,传回CPU芯片中,通过ALU完成计算后获得最后的结果存回寄存器中。
内存模型
linux有三种内存模型:平滑内存模型,非连续内存模型,稀疏内存模型。内存模型在编译期就会确定下来。
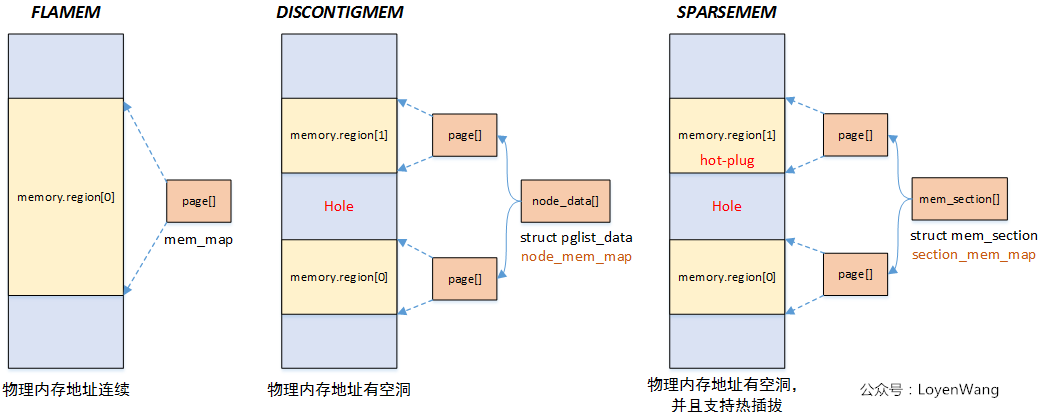
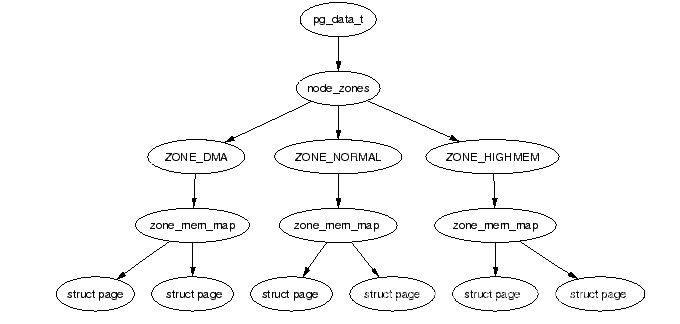
平滑内存模型
如图所示,可以看到物理地址是连续的。用一个全局变量mem_map的struct page数组存储所有的物理内存。从上面所学的页表的知识来看应该对应的就是单级页表,因为物理地址连续嘛。
非连续性内存模型
内存中有空洞,不是纯连续的内存。
每一段连续的物理内存都有一个pglist_data结构体对应,其成员node_mem_map是struct page指针,指向一个page结构体数组,不知道这里的连续内存是不是也是以页为单位的,应该是,不然这个page数组应该会存在不满一页的情况,想想就很麻烦。
同样有一个全局变量node_data,为struct pglist_data的数组,存储着所有的pglist_data指针。大小为MAX_NUMNODES
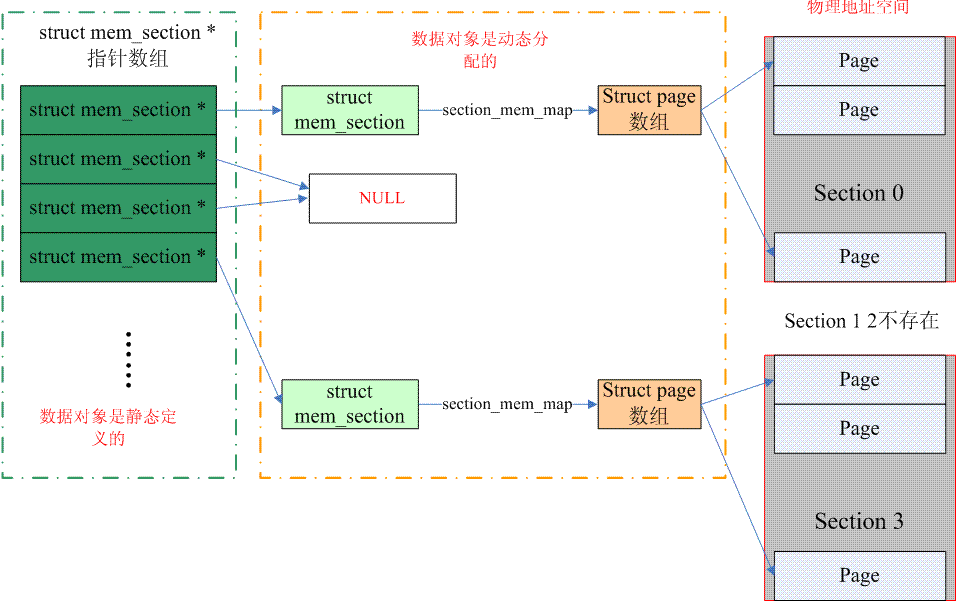
稀疏内存模型
也是现在最常用的模型。在mem_section结构体中存在section_mem_map成员指向一个page数组对应一段连续的物理内存。把内存按照section为单位分段。
存在一个全局的指针数组mem_section(同名)存放所有mem_section指针,指向理论上支持的物理空间。可能section对应的物理内存不存在,这会让此section的指针指向NULL。支持内存热拔插。
为什么非连续性内存模型不支持热插拔而稀疏内存模型支持热插拔呢?因为非连续性内存模型的节点粒度太粗了,说人话就是一个node_mem_map指向的page数组对应的物理内存太大了。热插拔内存有时并不需要这么大的内存,而随意拆分的成本非常高,所以非连续性内存模型被淘汰,取而代之的是稀疏内存模型。粒度较小,可以满足任意大小的内存插拔(当然以page为基础单位)(当然得有这么大内存)。于是被沿用到现在。
buddy system
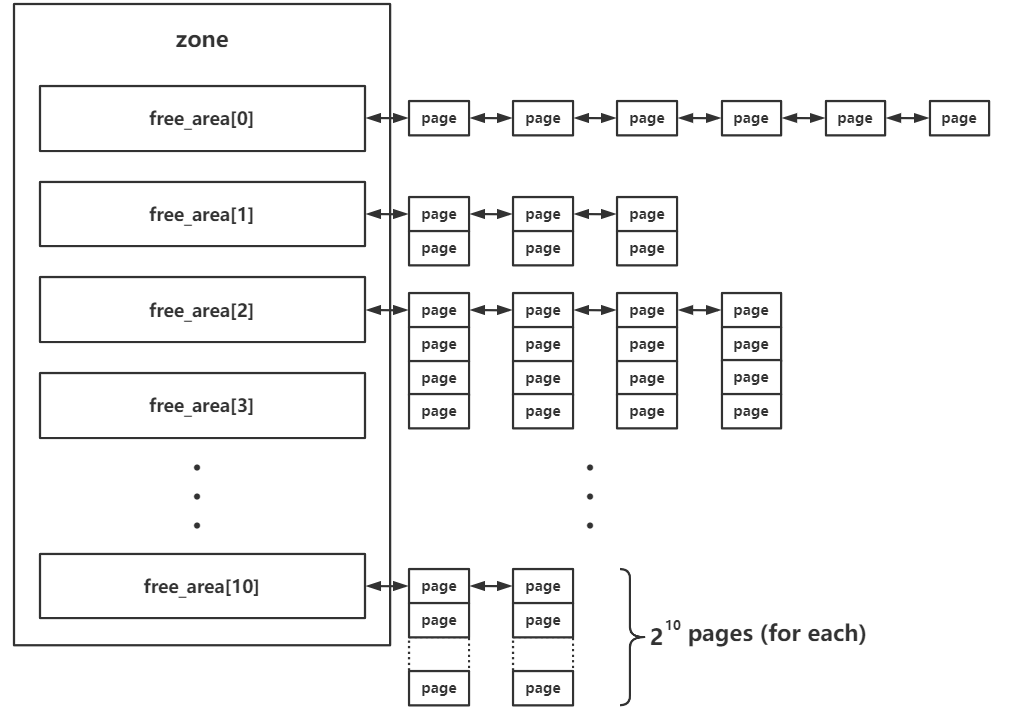
linux kernel的较为底层的内存管理系统。以内存页为粒度管理所有物理内存。存在于zone级别。对当前zone的所有物理页框进行管理。
每个zone都有一个free_area结构体数组,存储buddy system按照order管理的页面。
1 | struct zone { |
MAX_ORDER为常数11.
order含义是连续的空闲页面的大小,单位是阶。每个下标存储的页面大小是2的order次方页
分配
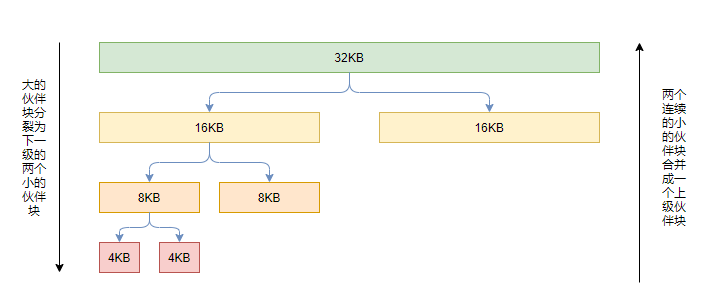
- 将请求的空间大小向2的幂次方大小的页对齐,向上取整,然后从对应下标取出连续内存页。
- 如果对应下标为空,即往下一个order处取出内存页,一分为二装到当前order链表中。如果下一个为空即寻找下下一个。
释放
- 对应的连续内存页放到对应的order的链表上
- 如果有可以合并的内存页,即合并然后放到下一个order中
感觉就是2048啊
这样操作很容易产生不容易合并的内存碎片,所以linux会进行内存迁移来减少内存碎片。用一个持续运行的内核线程完成。
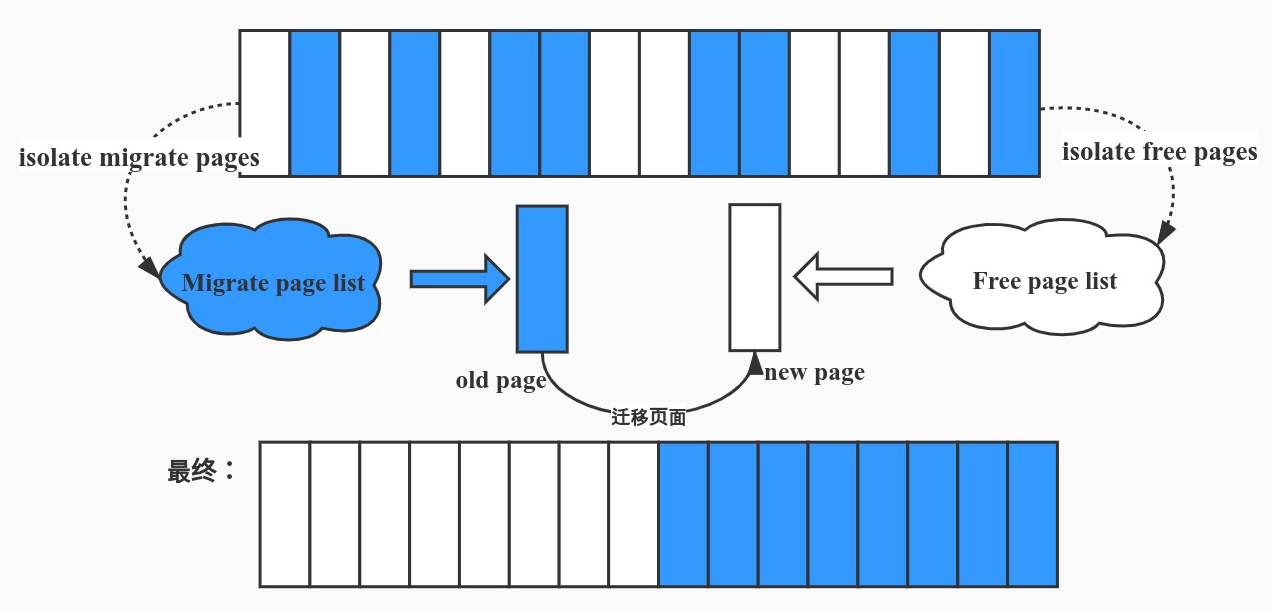
slab allocator
和buddy system相比更加细粒度的内存管理器。向buddy system请求单张或多张内存页后分割为同等大小对象后返回给上层调用者。
主要讲slub版本,现在大部分linux主流使用。基本结构如下
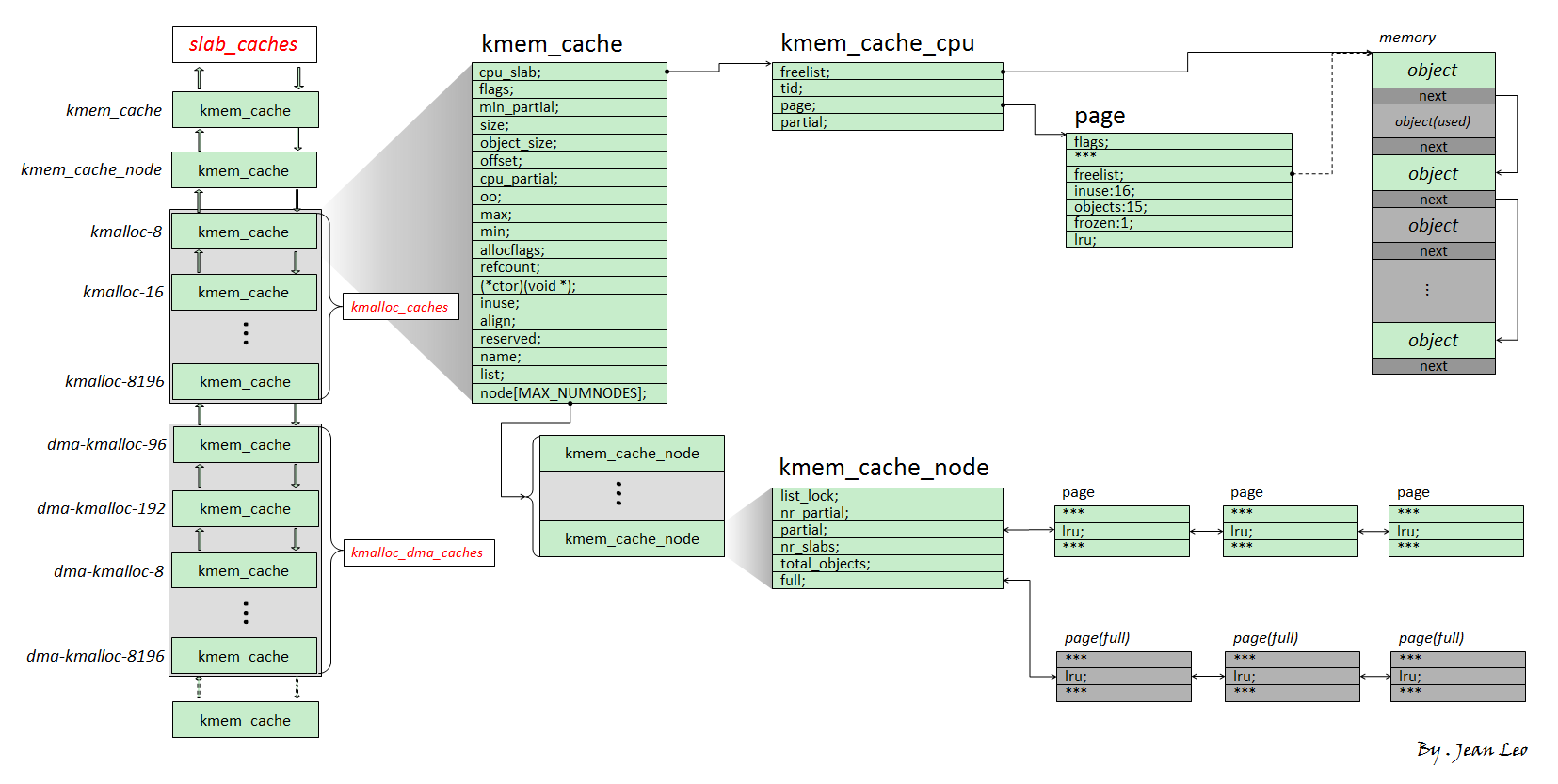
我们将 slub allocator 每次向 buddy system 请求得来的单张或者多张内存页称之为一个 slub,其被分割为多个同等大小object,每个object作为一个被分配实体,在 slub 的第一张内存页对应的 page 结构体上的 freelist 成员指向该张内存页上的第一个空闲对象,一个 slub 上的所有空闲对象组成一个以 NULL 结尾的单向链表
一个 object 可以理解为用户态 glibc 中的 chunk,不过 object 并不像 chunk 那样需要有一个 header,因为 page 结构体与物理内存间存在线性对应关系,我们可以直接通过 object 地址找到其对应的 page 结构体
kmem_cache为一个基本的 allocator 组件,其用于分配某个特定大小的对象,所有的 kmem_cache 构成一个双向链表,并存在两个对应的结构体数组kmalloc_caches与kmalloc_dma_caches一个
kmem_cache主要由两个模块组成:kmem_cache_cpu:这是一个percpu 变量(即每个核心上都独立保留有一个副本,原理是以 gs 寄存器作为 percpu 段的基址进行寻址),用以表示当前核心正在使用的 slub,因此当前 CPU 在从 kmem_cache_cpu 上取 object 时不需要加锁,从而极大地提高了性能
这里不加锁的原因详细解释一下。不是因为每个核心单独维护一个slub就不用加锁了。因为对象分配过程中调度器接入后可能触发任务切换,当前执行的任务可能调度到另一个核中运行。这样分配的时候不是在同一个核,但是中断处理程序取对象可能还是从同一个slub。为了保证是对象分配在同一个核上,且分配过程不被干扰,此处使用了一个字段tid
1
2
3
4
5
6
7
8
9
10struct kmem_cache_cpu {
/* 指向下一个空闲对象 */
void **freelist; /* Pointer to next available object */
/* 事务 ID, 用来做同步。kmem_cache_cpu 是分配对象的快速路径,因此性能是首要考虑因素,所以此处没有考虑使用加锁的方式来进行同步 */
unsigned long tid; /* Globally unique transaction id */
/*
* 指向当前 slab 的首个物理页面
*/
struct page *page; /* The slab from which we are allocating */
};这是一个全局递增的数字,slub在每次开始分配对象前会读取当前的tid数值,完成分配后将tid递增,然后用原子操作CAS来同时更新tid和freelist,这样如果中途有其他操作乱入,CAS操作会失败,slub就会重新开始分配,直到分配成功为止。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35/* file: mm/slub.c */
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node,
unsigned long addr,
size_t orig_size)
{
void *object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
redo:
/* 1. 分配逻辑开始时获取到当前 tid */
do {
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
} while (IS_ENABLED(CONFIG_PREEMPTION) &&
unlikely(tid != READ_ONCE(c->tid)));
/* 从当前 kmem_cache_cpu 的 free list 中拿到第一个对象 */
/* 2. 分配对象并计算下一个空闲对象的地址,即freelist 的新值*/
object = c->freelist;
void *next_object = get_freepointer_safe(s, object);
/* 3. 通过 CMPXCHG 指令设置 freelist 与 tid 的新值, 如果此时的 tid 与 s->cpu_slab->tid 不同,则说明发生了干扰,代码跳转到 redo 重新开始分配逻辑 */
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid, object,
tid, next_object, next_tid(tid)))) {
goto redo;
}
out:
return object;
}- kmem_cache_node可以理解为当前kmem_cache的 slub 集散中心,其中存放着两个 slub 链表:
- partial:该 slub 上存在着一定数量的空闲 object,但并非全部空闲
- full:该 slub 上的所有 object 都被分配出去了
分配/释放过程
- 分配:
- 首先从
kmem_cache_cpu上取对象,若有则直接返回 - 若
kmem_cache_cpu上的 slub 已经无空闲对象了,对应 slub 会被加入到kmem_cache_node的 full 链表,并尝试从 partial 链表上取一个 slub 挂载到kmem_cache_cpu上,然后再取出空闲对象返回 - 若
kmem_cache_node的 partial 链表也空了,那就向 buddy system 请求分配新的内存页,划分为多个 object 之后再给到kmem_cache_cpu,取空闲对象返回上层调用
- 首先从
- 释放:
- 若被释放 object 属于
kmem_cache_cpu的 slub,直接使用头插法插入当前 CPU slub 的 freelist - 若被释放 object 属于
kmem_cache_node的 partial 链表上的 slub,直接使用头插法插入对应 slub 的 freelist - 若被释放 object 属于
kmem_cache_node的 full 链表上的 slub,则其会成为对应 slub 的 freelist 头节点,且该 slub 会从 full 链表迁移到 partial 链表
- 若被释放 object 属于
slab alias
slab alias 机制是一种对同等/相近大小 object 的 kmem_cache 进行复用的一种机制:
- 当一个
kmem_cache在创建时,若已经存在能分配相等/近似大小的 object 的kmem_cache,则不会创建新的 kmem_cache,而是为原有的 kmem_cache 起一个 alias(别名),作为“新的” kmem_cache 返回
cred_jar 是专门用以分配 cred 结构体的 kmem_cache,在Linux 4.4 之前的版本中,其为 kmalloc-192 的 alias,即 cred 结构体与其他的 192 大小的 object 都会从同一个 kmem_cache——kmalloc-192 中分配
对于初始化时设置了 SLAB_ACCOUNT 这一 flag 的 kmem_cache 而言,则会新建一个新的 kmem_cache 而非为原有的建立 alias,如在新版的内核当中 cred_jar 与 kmalloc-192 便是两个独立的 kmem_cache,彼此之间互不干扰
参考
偷了很多图,如有侵权即刻删除(x
https://www.cnblogs.com/binlovetech/p/17571929.html
https://arttnba3.cn/2021/02/21/OS-0X00-LINUX-KERNEL-PART-I
https://blog.csdn.net/yhb1047818384/article/details/114454299
https://s3.shizhz.me/linux-mm/3.2-wu-li-nei-cun/3.2.5-slab-slub-slob




