
rust学习笔记
因为好奇而学一波rust,随时可能退坑。记录只记对自己重要的部分,查漏补缺用
rustlings和圣经同步学习,包含大量圣经原文原代码,主要是想抄一遍记忆更深刻,rustling遇到后才看圣经
rust圣经学习
基础概念
入门
变量绑定
rust核心原则——所有权。任何内存对象都有主人,绑定就是把这个对象绑定给一个变量,让这个变量成为他的主人。同时该变量之前的主人回丧失对该对象的所有权。
变量可变性
默认情况rust变量不可变,不过加上mut关键字可以让其变成可变的。
下划线开头忽略未使用变量
用下划线开头的变量,如果后面没有被使用不会被警告。不用下划线开头会被警告
变量和常量的差异
常量不用mut,且自始自终不可变,编译完成后值已经确定
用const关键字而不是let声明,且值的类型必须标注
1 | const MAX_POINTS: u32 = 100_000; |
变量遮蔽
rust允许声明相同变量名,后面声明的变量会遮蔽之前的
和mut不一样,如果let声明的变量名字相同,他们只是恰巧名字相同,实际上指向的是不同的内存地址,涉及到内存的再分配。而mut关键字指定的变量赋值是访问的同一个内存地址,不会涉及内存对象再分配,性能更好。
用处是,如果在某个作用域不需要使用之前的变量,可以重复用变量名字而不用在想一个
基本类型
函数
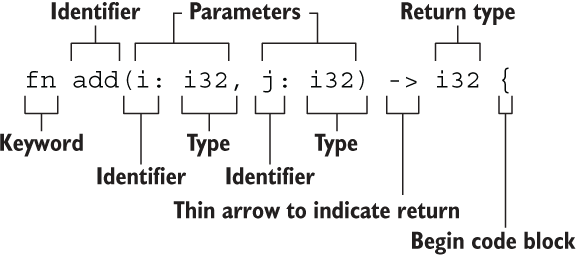
主要是这个图。
函数名和变量名用蛇形命名法
函数位置随意摆放
每个函数参数都要标注类型,因为是强类型语言
语句和表达式
这两个在rust里是严格进行区分了,语句是一个操作,不会返回值,但是表达式返回的是值,且总要返回值
函数返回
rust的函数就是表达式,可以把函数的返回值直接给调用者
函数的返回值就是最后一条表达式的返回值
可以用return提前返回
1 | fn plus_or_minus(x:i32) -> i32 { |
又有return又用表达式作返回值的函数
以 ; 结尾的是语句,而函数返回值需要是表达式。如果是下图的形式,会返回()
1 | fn add(x:u32,y:u32) -> u32 { |
所有权和借用
从内存中申请空间存放程序运行内容和释放这些空间是编程语言设计的重中之重,有三种流派
- 垃圾回收机制(GC):程序运行时不断寻找不被使用的内存,比如go和java
- 手动管理内存分配和释放:用函数调用的方式申请和释放内存,比如c++
- 通过所有权来管理:编译时会根据一系列规则进行检查
rust用的是第三种,这种检查只发生在编译期,对运行没有影响
所有权原则
三个重要的规则
1 | Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者 |
变量作用域
作用域是一个变量在程序中有效的范围
1 | { // s 在这里无效,它尚未声明 |
变量绑定背后的数据交互
转移所有权
1 | let x = 5; |
这种基本类型的拷贝很快,因为存储在栈上,且这种自动拷贝对性能的要求很低,只需要去栈里复制一个i32就行了,相比于去堆里创建内存
将 5 绑定到变量 x;接着拷贝 x 的值赋给 y,最终 x 和 y 都等于 5
1 | let s1 = String::from("hello"); |
此处和上面不一样,因为String不是基本类型,而且存在堆上
string是一个复杂类型,由存储在栈中的堆指针,字符串长度,字符串容量共同组成。堆指针最重要。
总之 String 类型指向了一个堆上的空间,这里存储着它的真实数据,下面对上面代码中的 let s2 = s1 分成两种情况讨论:
- 拷贝
String和存储在堆上的字节数组 如果该语句是拷贝所有数据(深拷贝),那么无论是String本身还是底层的堆上数据,都会被全部拷贝,这对于性能而言会造成非常大的影响 - 只拷贝
String本身 这样的拷贝非常快,因为在 64 位机器上就拷贝了8字节的指针、8字节的长度、8字节的容量,总计 24 字节,但是带来了新的问题,还记得我们之前提到的所有权规则吧?其中有一条就是:一个值只允许有一个所有者,而现在这个值(堆上的真实字符串数据)有了两个所有者:s1和s2。
如果一个值可以拥有两个所有者,会发生什么呢?
当变量离开作用域后,Rust 会自动调用 drop 函数并清理变量的堆内存。不过由于两个 String 变量指向了同一位置。这就有了一个问题:当 s1 和 s2 离开作用域,它们都会尝试释放相同的内存。这是pwn题目堆相关题目经典漏洞点double free,也是之前提到过的内存安全性 BUG 之一。两次释放(相同)内存会导致内存污染,它可能会导致潜在的安全漏洞。
因此,Rust 这样解决问题:当 s1 赋予 s2 后,Rust 认为 s1 不再有效,因此也无需在 s1 离开作用域后 drop 任何东西,这就是把所有权从 s1 转移给了 s2,s1 在被赋予 s2 后就马上失效了。
1 | fn main() { |
这种又不一样,因为上个例子s1是获得了String的所有权,而此处x只是获得了这个字符串的引用并未获得所有权,所以可以正常输出
拷贝(浅拷贝)
只发生在栈上,性能很高
1 | let x = 5; |
这段代码不会报所有权错误,因为常量这种基本类型在编译的时候就已经是已知大小的,会被存在栈上,所以拷贝它很快速,所以没有理由让y被赋值后让x无效。rust有一个Copy的特征,可以用在这种存在栈上的类型,如果类型拥有Copy特征,一个旧的变量在被赋值给其他变量后仍然可以使用
任何基本类型的组合可以 Copy ,不需要分配内存或某种形式资源的类型是可以 Copy 的。
- 所有整数类型,比如
u32 - 布尔类型,
bool,它的值是true和false - 所有浮点数类型,比如
f64 - 字符类型,
char - 元组,当且仅当其包含的类型也都是
Copy的时候。比如,(i32, i32)是Copy的,但(i32, String)就不是 - 不可变引用
&T,例如转移所有权中的最后一个例子,但是注意: 可变引用&mut T是不可以 Copy的
克隆(深拷贝)
rust永远都不会自动创建数据的深拷贝,所以任何自动的复制都不是深拷贝
如果确实需要深度复制string中堆上的数据,而不仅仅是栈上的,可以用clone函数
1 | let s1 = String::from("hello"); |
完整复制了s1的数据到s2
复合类型
数组
rust常用数组:速度快但是长度固定的array,可动态增长但是有性能损耗的Vector
创建数组
1 | fn main() { |
array是存储在栈上,Vector存储在堆上,长度可以动态改变
为数组声明类型
1 | let a: [i32; 5] = [1, 2, 3, 4, 5]; |
通过方括号语法声明,分号后面的数字 5 是数组长度,数组的元素类型要统一,长度要固定。
使用下面的语法初始化一个某个值重复出现 N 次的数组:
1 | let a = [3; 5]; |
切片
其他语言很多,rust如下
1 | let s = String::from("hello world"); |
左闭右开,和python一样
以下两种是等价的
1 | let slice = &s[0..2]; |
字符串字面量是切片
1 | let s = "Hello, world!"; |
类似上面的这个定义,其中s的数据类型实际是&str.这也是为什么字符串字面量不变,因为&str是不可变引用
字符串
追加
可以用push()方法追加字符char,也可以用push_str()方法追加字符串。两个方法都是在原有的字符串上追加,不会返回新的字符串。由于字符串追加操作要修改原来的字符串,所以该字符串必须为mut修饰的
插入
insert插一个,insert_str插入字符串。第一个参数是下标第二个是插入的东西,其他的和追加一样
替换
- replace
和python用法差不多,返回一个新的字符串,而不是操作原来的字符串 xx.replace()
- replacen
这个有三个参数,第三个参数决定替换几个,返回一个新的字符串,而不是操作原来的字符串
- replace_range
只用于string类型,第一个参数是要替换字符串的范围(Range),第二个参数是新的字符串。直接操作原来的字符串,不会返回新的字符串。需要使用 mut 关键字修饰。
1 | fn main() { |
删除
- pop
常规,只是返回值是弹出的字符
- remove
删除指定位置字符,直接操作原来的字符串。但是存在返回值,其返回值是删除位置的字符串,
- truncate
删除字符串中从指定位置开始到结尾的全部字符,该方法是直接操作原来的字符串,无返回值
- clear
常规
连接
直接+或+=,但是要求右边参数必须是字符串切片类型,也就是要是引用&
+是返回新字符串,所以可以不用mut,但是+=要
1 | fn main() { |
1 | let s1 = String::from("tic"); |
操作UTF8字符串
字符
如果你想要以 Unicode 字符的方式遍历字符串,最好的办法是使用 chars 方法,例如:
1 | for c in "中国人".chars() { |
1 | 中 |
字节
这种方式是返回字符串的底层字节数组表现形式:
1 | for b in "中国人".bytes() { |
输出如下:
1 | 228 |
主要是注意用char()还是bytes()
结构体
和c++的差不多,结构如下
1 | struct User { |
创建实例
看例子就懂了
1 | let user1 = User { |
注意初始化时每个字段都要初始化
访问结构体内字段
1 | let mut user1 = User { |
注意rust里面不支持把结构体的某个元素设置为可变的,只支持将整个结构体实例声明为可变。只有实例可变才能修改内部字段
简化结构体创建
1 | fn build_user(email: String, username: String) -> User { |
当函数参数和结构体字段同名时,可以直接使用缩略的方式进行初始化,跟 TypeScript 中一模一样。
结构体更新语法
用一个结构体赋值另一个结构体
1 | let user2 = User { |
很奇妙的写法,但是很方便
user2只有email字段和user1不同,所以我们只改email,剩下的直接用..user1更新就可以
.. 语法表明凡是我们没有显式声明的字段,全部从 user1 中自动获取。需要注意的是 ..user1 必须在结构体的尾部使用。
结构体内存排列
1 |
|
上面定义的 File 结构体在内存中的排列如下图所示:
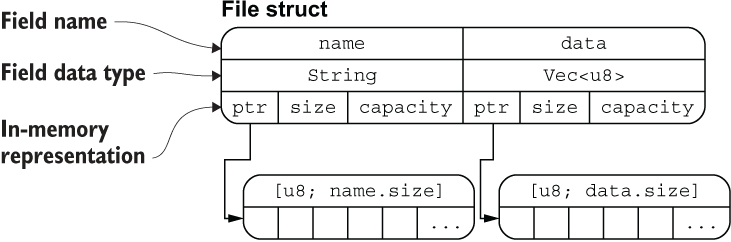
从图中可以清晰地看出 File 结构体两个字段 name 和 data 分别拥有底层两个 [u8] 数组的所有权(String 类型的底层也是 [u8] 数组),通过 ptr 指针指向底层数组的内存地址,这里你可以把 ptr 指针理解为 Rust 中的引用类型。
该图片也侧面印证了:把结构体中具有所有权的字段转移出去后,将无法再访问该字段,但是可以正常访问其它的字段。
元组结构体
结构体字段可以没有名称,叫元组结构体
1 | struct Color(i32, i32, i32); |
单元结构体
如果不关注类型的内容只关注行为可以使用
1 | struct AlwaysEqual; |
枚举
和c语言的差不多
通过::访问枚举类型下的具体成员
1 | fn main() { |
print_suit 函数的参数类型是 PokerSuit,因此我们可以把 heart 和 diamond 传给它,虽然 heart 是基于 PokerSuit 下的 Hearts 成员实例化的,但是它是货真价实的 PokerSuit 枚举类型。这里注意
实现扑克牌
1 | enum PokerSuit { |
通过设置结构体的第一个元素为扑克牌类型的枚举,实现用结构体分别表示牌类型和值
1 | enum PokerCard { |
这样也行
泛型和特征
泛型Generics
感觉就是模板类,防止函数只是因为传参类型不同而重写很多次导致代码体积膨胀,引入泛型,在编译期的时候才进行单态化
基本用法
使用泛型参数,必须在使用前对其进行声明
1 | fn largest<T>(list: &[T]) -> T { |
largest
以下是错误案例
1 | fn largest<T>(list: &[T]) -> T { |
主要是这个地方
1 | if item > largest { |
因为传入的参数不一定和largest是可比较的类型,所以会报错。这里需要根据报错限定一下T类型
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> T { |
结构体泛型
1 | struct Point<T,U> { |
如代码所示,同样需要声明,如果出现xy类型不一样的话需要用不同的字母表示
方法泛型
同样需要声明impl
1 | struct Point<T> { |
注意这里结构体的名称是Point
为具体泛型实现方法
1 | impl Point<f32> { |
如图,如果传入参数是f32类型的就会执行这个方法,同样可以写另一个方法参数是u32的,根据传入参数数据类型的不同也会走到不同的函数
特征Trait
和接口很像
特征定义了一组可以被共享的行为,只要实现了特征,你就能使用这组行为
定义
1 | pub trait Summary { |
如代码所示,如果有不同的结构体需要使用同一种方法,可以用特征来定义。不需要给出特征的方法的内容,而是在impl里编写具体的实现
1 | pub struct Post { |
然后就可以
1 | fn main() { |
孤儿规则
如果你想要为类型 A 实现特征 T,那么 A 或者 T 至少有一个是在当前作用域中定义的
这是为了防止破坏其他人写的代码或者被别人破坏自己代码
默认实现
很容易理解
1 | pub trait Summary { |
使用特征作为函数参数
1 | pub fn notify(item: &impl Summary) { |
它的意思是 实现了Summary特征 的 item 参数。可以看到可以调用Summary定义的summarize方法
可以使用任意实现了Summary特征的类型作为函数的参数
特征约束
虽然 impl Trait 这种语法非常好理解,但是实际上它只是一个语法糖:
1 | pub fn notify<T: Summary>(item: &T) { |
真正的完整书写形式,形如 T: Summary 被称为特征约束。
如果我们想要强制函数的两个参数是同一类型,我们只能使特征约束来实现:
1 | pub fn notify<T: Summary>(item1: &T, item2: &T) {} |
如果是不同类型的话,用语法糖的形式即可
多重约束
可以指定多个约束条件,让参数实现多个特征
1 | pub fn notify(item: &(impl Summary + Display)) {} |
如代码所示
Where约束
特征约束多的时候可以用这个简化一下
1 | fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {} |
函数返回中的impl Trait
可以返回trait来表示函数返回的是一个类型,但是必须是具体类型
1 | fn returns_summarizable() -> impl Summary { |
如果不是具体类型会报错
1 | fn returns_summarizable(switch: bool) -> impl Summary { |
此代码返回值可能是Weibo也可能是Post,所以不行
模式匹配
match&if let
match用起来和switch一样,代码例子如下
1 | enum Direction { |
用match表达式赋值
1 | enum IpAddr { |
模式绑定
同样是举例子就可以看懂
1 | enum UsState { |
1 | fn value_in_cents(coin: Coin) -> u8 { |
如果我们想知道Quarter的参数UsState是啥,我们可以在match匹配到的时候把它打印出来,通过把这个参数绑定到state上的方法。和frida hook函数感觉差不多
if let匹配
如果我们只想匹配一个模式,就用if let,如果匹配多个的话就用match
以下两个同理
1 | let v = Some(3u8); |
1 | if let Some(3) = v { |
matches!宏
一个很实用的宏,可以将一个表达式和模式进行匹配,然后返回匹配结果
1 | enum MyEnum { |
现在如果想对 v 进行过滤,只保留类型是 MyEnum::Foo 的元素
1 | v.iter().filter(|x| matches!(x, MyEnum::Foo)); |
很简单也很简洁,再来看看更多的例子:
1 | let foo = 'f'; |
变量遮蔽
无论是 match 还是 if let,这里都是一个新的代码块,而且这里的绑定相当于新变量,如果你使用同名变量,会发生变量遮蔽:
1 | fn main() { |
cargo run 运行后输出如下:
1 | 在匹配前,age是Some(30) |
可以看出在 if let 中,= 右边 Some(i32) 类型的 age 被左边 i32 类型的新 age 遮蔽了,该遮蔽一直持续到 if let 语句块的结束。因此第三个 println! 输出的 age 依然是 Some(i32) 类型。
对于 match 类型也是如此:
1 | fn main() { |
需要注意的是,**match 中的变量遮蔽其实不是那么的容易看出**,因此要小心!其实这里最好不要使用同名,避免难以理解,如下。
1 | fn main() { |
option解构
option就是枚举
1 | enum Option<T> { |
匹配Option<T>
作用的话rustlings的quiz2里面能深刻感觉到,可以和match配合,简洁高效的进行不同类型的case的识别和处理
示例如下
1 | fn plus_one(x: Option<i32>) -> Option<i32> { |
包和模块
模块
感觉就像代码的作用空间一样
创建嵌套模块
看起来有点像类,但是又有点不像
1 | mod front_of_house { |
- 使用
mod关键字来创建新模块,后面紧跟着模块名称 - 模块可以嵌套
- 模块中可以定义各种 Rust 类型,例如函数、结构体、枚举、特征等
- 所有模块均定义在同一个文件中
模块树
和之前操作系统写的pstree结构一样
1 | crate |
crate是根,相当于linux的 / 根目录
用路径引用模块
想调用一个函数,得知道它的路径
- 绝对路径,从包根开始,路径名以包名或者
crate作为开头 - 相对路径,从当前模块开始,以
self,super或当前模块的标识符作为开头
1 | mod front_of_house { |
下面的相对路径是因为这一句代码已经在crate模块中了,所以可以直接用front_of_house
代码可见性
1 | mod front_of_house { |
运行后意料之外的报错了,毕竟看上去确实很简单且没有任何问题:
1 | error[E0603]: module `hosting` is private |
hosting 模块是私有的,无法在包根进行访问,那么为何 front_of_house 模块就可以访问?因为它和 eat_at_restaurant 同属于一个包根作用域内,同一个模块内的代码自然不存在私有化问题(所以我们之前章节的代码都没有报过这个错误!)。
在 Rust 中,父模块完全无法访问子模块中的私有项,但是子模块却可以访问父模块、父父..模块的私有项。
pub关键字
和其他语言的public差不多,注意如果要调用模块内部的函数,不仅模块要pub函数也要pub
用super引用模块
1 | fn serve_order() {} |
用super::调用父模块的serve_order函数
结构体和枚举的可见性
- 将结构体设置为
pub,但它的所有字段依然是私有的 - 将枚举设置为
pub,它的所有字段也将对外可见
原因在于,枚举和结构体的使用方式不一样。如果枚举的成员对外不可见,那该枚举将一点用都没有,因此枚举成员的可见性自动跟枚举可见性保持一致,这样可以简化用户的使用。
模块和文件分离
在之前的例子中,我们所有的模块都定义在 src/lib.rs 中,但是当模块变多或者变大时,需要将模块放入一个单独的文件中,让代码更好维护。
现在,把 front_of_house 前厅分离出来,放入一个单独的文件中 src/front_of_house.rs:
1 | pub mod hosting { |
然后,将以下代码留在 src/lib.rs 中:
1 | mod front_of_house; |
so easy!其实跟之前在同一个文件中也没有太大的不同,但是有几点值得注意:
mod front_of_house;告诉 Rust 从另一个和模块front_of_house同名的文件中加载该模块的内容- 使用绝对路径的方式来引用
hosting模块:crate::front_of_house::hosting;
需要注意的是,和之前代码中 mod front_of_house{..} 的完整模块不同,现在的代码中,模块的声明和实现是分离的,实现是在单独的 front_of_house.rs 文件中,然后通过 mod front_of_house; 这条声明语句从该文件中把模块内容加载进来。因此我们可以认为,模块 front_of_house 的定义还是在 src/lib.rs 中,只不过模块的具体内容被移动到了 src/front_of_house.rs 文件中。
在这里出现了一个新的关键字 use,联想到其它章节我们见过的标准库引入 use std::fmt;,可以大致猜测,该关键字用来将外部模块中的项引入到当前作用域中来,这样无需冗长的父模块前缀即可调用:hosting::add_to_waitlist();,在下节中,我们将对 use 进行详细的讲解。
当一个模块有许多子模块时,我们也可以通过文件夹的方式来组织这些子模块。
在上述例子中,我们可以创建一个目录 front_of_house,然后在文件夹里创建一个 hosting.rs 文件,hosting.rs 文件现在就剩下:
1 | pub fn add_to_waitlist() {} |
现在,我们尝试编译程序,很遗憾,编译器报错:
1 | error[E0583]: file not found for module `front_of_house` |
是的,如果需要将文件夹作为一个模块,我们需要进行显示指定暴露哪些子模块。按照上述的报错信息,我们有两种方法:
- 在
front_of_house目录里创建一个mod.rs,如果你使用的rustc版本1.30之前,这是唯一的方法。 - 在
front_of_house同级目录里创建一个与模块(目录)同名的 rs 文件front_of_house.rs,在新版本里,更建议使用这样的命名方式来避免项目中存在大量同名的mod.rs文件( Python 点了个踩)。
而无论是上述哪个方式创建的文件,其内容都是一样的,你需要定义你的子模块(子模块名与文件名相同):
1 | pub mod hosting; |
集合类型
HashMap
和其他语言的hashmap一个东西,key-value,主要是看看rust的hashmap的函数调用是咋回事
用new创建
1 | use std::collections::HashMap; |
注意HashMap需要use来引入,因为它没有加到prelude里面
用迭代器和collect创建
1 | fn main() { |
1 | fn main() { |
两个方法,上面是笨方法(我能想到的方法),下面是比较快的方法。下面是把teams_list先转成迭代器,然后用collect收集。HashMap<_,_>意思是让编译器帮你去判断是什么类型,非常方便。只是不知道这种方式安不安全
所有权转移
- 若类型实现
Copy特征,该类型会被复制进HashMap,因此无所谓所有权 - 若没实现
Copy特征,所有权将被转移给HashMap中
1 | fn main() { |
运行代码,报错如下:
1 | error[E0382]: borrow of moved value: `name` |
提示很清晰,name 是 String 类型,因此它受到所有权的限制,在 insert 时,它的所有权被转移给 handsome_boys,所以最后在使用时,会遇到这个无情但是意料之中的报错。
如果你使用引用类型放入 HashMap 中,请确保该引用的生命周期至少跟 HashMap 活得一样久:
1 | fn main() { |
上面代码,我们借用 name 获取了它的引用,然后插入到 handsome_boys 中,至此一切都很完美。但是紧接着,就通过 drop 函数手动将 name 字符串从内存中移除,再然后就报错了:
1 | handsome_boys.insert(&name, age); |
查询hashmap
用get查,传入key返回value
1 | use std::collections::HashMap; |
get方法返回一个Option<&i32>类型:当查询不到时,会返回一个None,查询到时返回Some(&i32)&i32是对HashMap中值的借用,如果不使用借用,可能会发生所有权的转移
如果想直接获得值类型的score
1 | let score: i32 = scores.get(&team_name).copied().unwrap_or(0); |
unwrap_or 是一个用于处理 Option 类型的方法,它允许你从 Option 中取出值,如果 Option 是 None,则提供一个默认值。这里是0.所以如果返回正常的话就是获得值的类型
如果用循环方式遍历
1 | use std::collections::HashMap; |
更新hashmap
看代码就懂了
1 | fn main() { |
1 | use std::collections::HashMap; |
计算字符串出现的字数
返回值和错误处理
返回值Result和?
?居然是一个宏,笑死我了
1 | enum Result<T, E> { |
首先是这个枚举类型Result,里面有两个元素,一个是Ok一个是Err。返回类型是Ok的时候,Ok(T)的T存放的是成功后存入的正确值的类型,E代表错误时存放的错误值
如果用一个错误的数据类型作为File::open的返回值
1 | let f: u32 = File::open("hello.txt"); |
报错如下
1 | error[E0308]: mismatched types |
提示返回类型是std::result::Result<std::fs::File, std::io::Error>,看起来很复杂,其实不然,就是Result<T, E>而已。T这里作为模板,是返回的File句柄,如果成功返回的话。E是返回的错误类型,这里是IO错误。最外层的Result更不用说。也可以ctrl+鼠标左键看源代码去查看返回类型
正确应该这样编写
1 | use std::fs::File; |
处理返回的错误
返回的错误有很多,如果都用panic不是很好
1 | use std::fs::File; |
不咋需要解释,看代码就行
unwrap和expect
如果不想管这么多,错了直接崩溃得了,可以用这俩函数
1 | use std::fs::File; |
如果hello.txt不存在,这里直接panic
expect和unwrap的区别是,expect可以带自己写的错误信息
1 | use std::fs::File; |
?
很牛逼的宏,各种意义上
1 | use std::fs::File; |
其中
1 | let mut f = match f { |
这两个是一样的。非常酷炫非常简洁
?还带有错误的自动类型转换功能,如果错误出现上下级,上级和下级同时出现,最外层返回的会转换成上级的错误。
1 | fn open_file() -> Result<File, Box<dyn std::error::Error>> { |
上面代码中 File::open 报错时返回的错误是 std::io::Error 类型,但是 open_file 函数返回的错误类型是 std::error::Error 的特征对象,可以看到一个错误类型通过 ? 返回后,变成了另一个错误类型,这就是 ? 的神奇之处。
?还能实现链式调用
1 | use std::fs::File; |
?常犯的错
1 | fn first(arr: &[i32]) -> Option<&i32> { |
这段代码无法通过编译,?操作符需要一个变量来承载正确的值,这个函数只会返回Some(&i32)或者None,只有错误值能直接返回,正确的值不行,所以如果数组中存在 0 号元素,那么函数第二行使用 ?后的返回类型为&i32而不是Some(&i32)。因此 ?` 只能用于以下形式:
let v = xxx()?;xxx()?.yyy()?;
带返回值的main
记录一下,不知道会不会用到
1 | use std::error::Error; |
rustlings练习
主要记录感觉重要的
- 24的vector,创建vec类型一般有两种方法,Vec::new()初始化一个然后一个个push进去,或者是vec![]然后在中括号里面填元素
- 26的vec的clone深拷贝。这个得结合之前的知识,首先是所有权问题,因为一个值只有一个所有者,所以代码里的fill_vec传进去后赋值后,之前的vec就失效了,返回的那个vec传入vec1,所以后面的assert会报错,因为vec已经失效了。所以这里用深拷贝clone,这样会生成一个新的vec对象,和原来的就不冲突了
- 29的变量的可变引用不能同时被多次借用,必须被改变或者使用后才能再次使用可变引用,这样是为了安全考虑,防止数据竞争。(真tm安全啊)
- 30 比较重要,虽然看它的注释能直接做出来,但是有几个问题现在暂时不是很懂
纯做出来的话,getchar是不用获得所有权,string_uppercase是需要获得所有权,所以getchar传参传引用,string_uppercase传所有权就可以了
但是我再想为什么string_uppercase不能传引用,传引用后赋值data会报错说变量被drop后赋值。网上查询发现是&str和string的生命周期问题,和rust的变量的释放有关,但是说实话还不是很懂。如果重新let一个变量然后把to_uppercase的返回值传给新变量就可以。emm之后深入学再回头看看
- 31 结构体,基本使用没啥好说的,但是用起来copilot后我还在想咋写呢就出来代码了,感觉是不是得先关掉(
- 36 关了copilot又不会写了,擦。本来想判断传入的类型,但是觉得也过于不优雅,网上搜了一下发现是用到了还没学过的语法match,麻了。学学学
- 47 知道啥思路但是写出来框框报错,和我想的有点不一样。
1 | let team_1 = scores.entry(team_1_name.clone()).or_insert(Team { goals_scored: 0, goals_conceded: 0 }); |
scores.entry(team_1_name.clone())返回的是hashmap,我原本是直接返回然后调用发现调用不了。然后发现加个or_insert后返回类型就变成了Team,就可以直接访问成员变量。还是感觉很神奇
- 48 quiz2,检验match的运用和数组的解构,还考察了字符串的基本操作,插入和去除空格的函数。还考了匿名函数,比较综合。需要注意的是match的case如果是其中有参数的话,用变量代替,且传入的时候是传入的引用,需要通过解引用来获得值
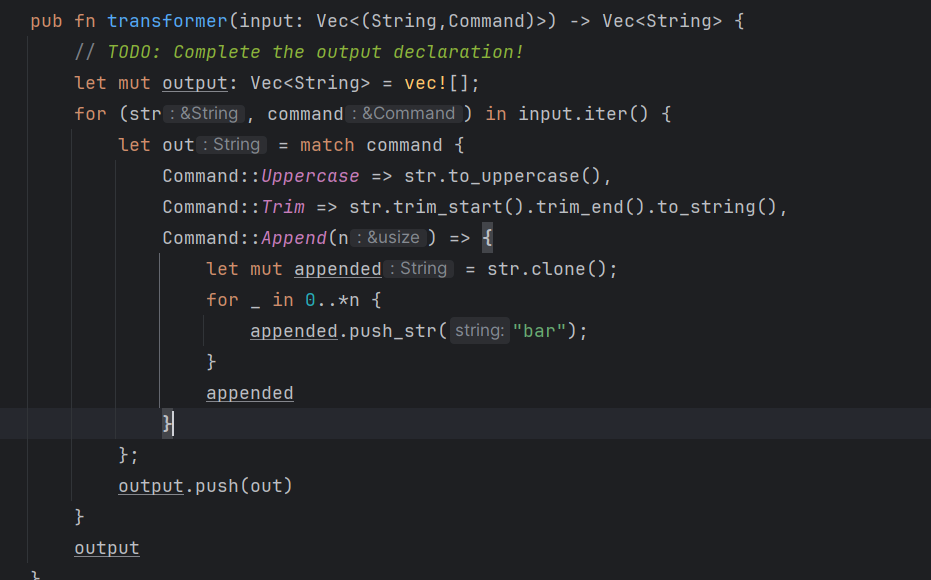
- 53 可以改main的返回值类型
- 55 用到了Box类型,
Box<dyn error::Error>是 Rust 中用于表示堆分配的实现了error::Errortrait 的错误类型的一种通用形式。将错误包装在Box<dyn error::Error>中的主要目的是进行动态分发和捕获。由于 Rust 的错误处理是基于类型的,因此在一些场景中,可能存在多种可能的错误类型。使用Box<dyn error::Error>允许捕获和传递任何实现了error::Errortrait 的错误类型,而无需事先知道确切的错误类型。这里需要用Box是因为这里返回的错误类型比较多,用这个可以不用管具体返回的类型 - 73 把vec数组转换成iterator的方法就是直接.into_iter(),最后又因为是可变数组(?)所以最后俩none不会报错溢出
- 74 因为不知道怎么返回Ok()的类型卡了半天,结果发现就是i32,直接collect然后转成Vec形式,元素都会套一层Ok.越学越觉得没搞懂。
还有collect()返回的是迭代器类型不能直接println需要先赋值给一个类型,确定迭代器的collect的返回类型后再进行打印,一般可以用division_results.collect::<Vec<_>>()来存到Vec里,不用直接判断类型 - 75 学到了一个函数用法fold。可以让一个迭代器进行一个累积操作并返回一个单一的值。比如
1 | (1..=num).fold(1, |acc, x| acc * x) |
就是返回阶乘,默认是1,也就是fold的第一个参数,然后后面根据迭代器的每个元素进行一个相乘的操作,acc是当前的累计值,所以最后返回的就是一个阶乘
77 智能指针Box,分配的是堆上的内存,可以在递归定义的类型里确定类型的大小
78 rc引用计数,在堆上分配一个包含引用计数的值,如果有对这个值的引用,引用计数就+1,没有引用就会减少,到0的时候就释放




